Technical Description
Architecture
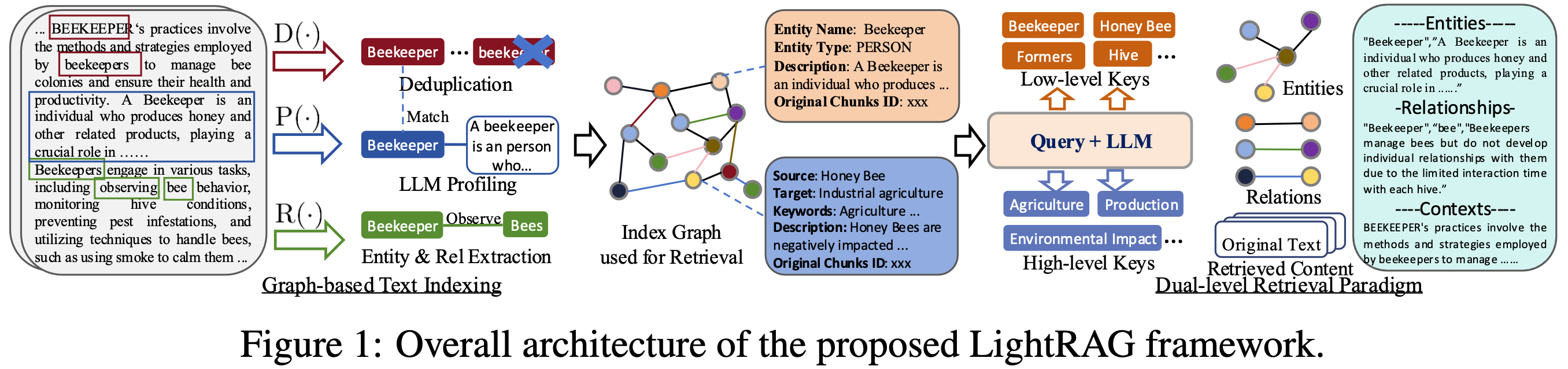
-
Graph-Enhanced Entity and Relationship Extraction. LightRAG enhances the
retrieval system by segmenting
documents into smaller, more manageable pieces. This strategy allows for quick
identification and access to relevant
information without analyzing entire documents. Next, we leverage LLMs to identify and
extract various entities (e.g.,
names, dates, locations, and events) along with the relationships between them. The
information collected through this
process will be used to create a comprehensive knowledge graph that highlights the
connections and insights across the
entire collection of documents. The functions used in our graph-based text indexing
paradigm are described as:
- Extracting Entities and Relationships \(\text{R}(\cdot)\): This function prompts a LLM to identify entities (nodes) and their relationships (edges) within the text data. For instance, it can extract entities like "Cardiologists" and "Heart Disease," and relationships such as "Cardiologists diagnose Heart Disease" from the text: "Cardiologists assess symptoms to identify potential heart issues." To improve efficiency, the raw text is segmented into multiple chunks.
- LLM Profiling for Key-Value Pair Generation \(\text{P}(\cdot)\): We employ a LLM-empowered profiling function to generate a text key-value pair for each entity node and relation edge. Each index key is a word or short phrase that enables efficient retrieval, while the corresponding value is a text paragraph summarizing relevant snippets from external data to aid in text generation. Entities use their names as the sole index key, whereas relations may have multiple index keys derived from LLM enhancements that include global themes from connected entities.
- Deduplication to Optimize Graph Operations \(\text{D}(\cdot)\): Finally, we implement a deduplication function that identifies and merges identical entities and relations from different segments of the raw text. This process effectively reduces the overhead associated with graph operations by minimizing the graph's size, leading to more efficient data processing.
-
Fast Adaptation to Incremental Knowledge Base. To efficiently adapt to evolving
data changes while ensuring
accurate and relevant responses, LightRAG incrementally updates the knowledge base
without the need for complete
reprocessing of the entire external database. The incremental update algorithm processes
new documents using the same
graph-based indexing steps as before. Subsequently, the model combines the new graph
data with the original by merging
the nodes and edges. Two key objectives guide our approach to fast adaptation for the
incremental knowledge base:
- Seamless Integration of New Data: By applying a consistent methodology to new information, the incremental update module allows the model to integrate new external databases without disrupting the existing graph structure. This approach preserves the integrity of established connections, ensuring that historical data remains accessible while enriching the graph without conflicts or redundancies.
- Reducing Computational Overhead: By eliminating the need to rebuild the entire index graph, this method reduces computational overhead and facilitates the rapid assimilation of new data. Consequently, the model maintains system accuracy, provides current information, and conserves resources, ensuring users receive timely updates and enhancing the overall RAG effectiveness.
-
Dual-level Retrieval Paradigm. To retrieve relevant information from both
specific document chunks and their
complex inter-dependencies, LightRAG proposes generating query keys at both detailed and
abstract levels.
- Specific Queries: These queries are detail-oriented and typically reference specific entities within the graph, requiring precise retrieval of information associated with particular nodes or edges. For example, a specific query might be, "Who wrote 'Pride and Prejudice'?"
- Abstract Queries: In contrast, abstract queries are more conceptual, encompassing broader topics, summaries, or overarching themes that are not directly tied to specific entities. An example of an abstract query is, "How does artificial intelligence influence modern education?"
- Low-Level Retrieval: This level is primarily focused on retrieving specific entities along with their associated attributes or relationships. Queries at this level are detail-oriented and aim to extract precise information about particular nodes or edges within the graph.
- High-Level Retrieval: This level addresses broader topics and overarching themes. Queries at this level aggregate information across multiple related entities and relationships, providing insights into higher-level concepts and summaries rather than specific details.
- Retrieval-Augmented Answer Generation. Utilizing the retrieved information, LightRAG employs a general-purpose LLM to generate answers based on the collected data. This data comprises concatenated values from relevant entities and relations, produced by the profiling function. It includes names, descriptions of entities and relations, and excerpts from the original text. By unifying the query with this multi-source text, the LLM generates informative answers tailored to the user's needs, ensuring alignment with the query's intent. This approach streamlines the answer generation process by integrating both context and query into the LLM model.
Experiments
Defining ground truth for many RAG queries, particularly those involving complex high-level semantics, poses significant challenges. To address this, we build on existing work and adopt an LLM-based multi-dimensional comparison method. We employ a robust LLM, specifically GPT-4o-mini, to rank each baseline against LightRAG. In total, we utilize four evaluation dimensions, including: i) Comprehensiveness: How thoroughly does the answer address all aspects and details of the question? ii) Diversity: How varied and rich is the answer in offering different perspectives and insights related to the question? iii) Empowerment: How effectively does the answer enable the reader to understand the topic and make informed judgments? iv) Overall: This dimension assesses the cumulative performance across the three preceding criteria to identify the best overall answer.
After identifying the winning answer for the three dimensions, the LLM combines the results to determine the overall better answer. To ensure a fair evaluation and mitigate the potential bias that could arise from the order in which the answers are presented in the prompt, we alternate the placement of each answer. We calculate win rates accordingly, ultimately leading to the final results.
Comparison of LightRAG with Existing RAG Methods
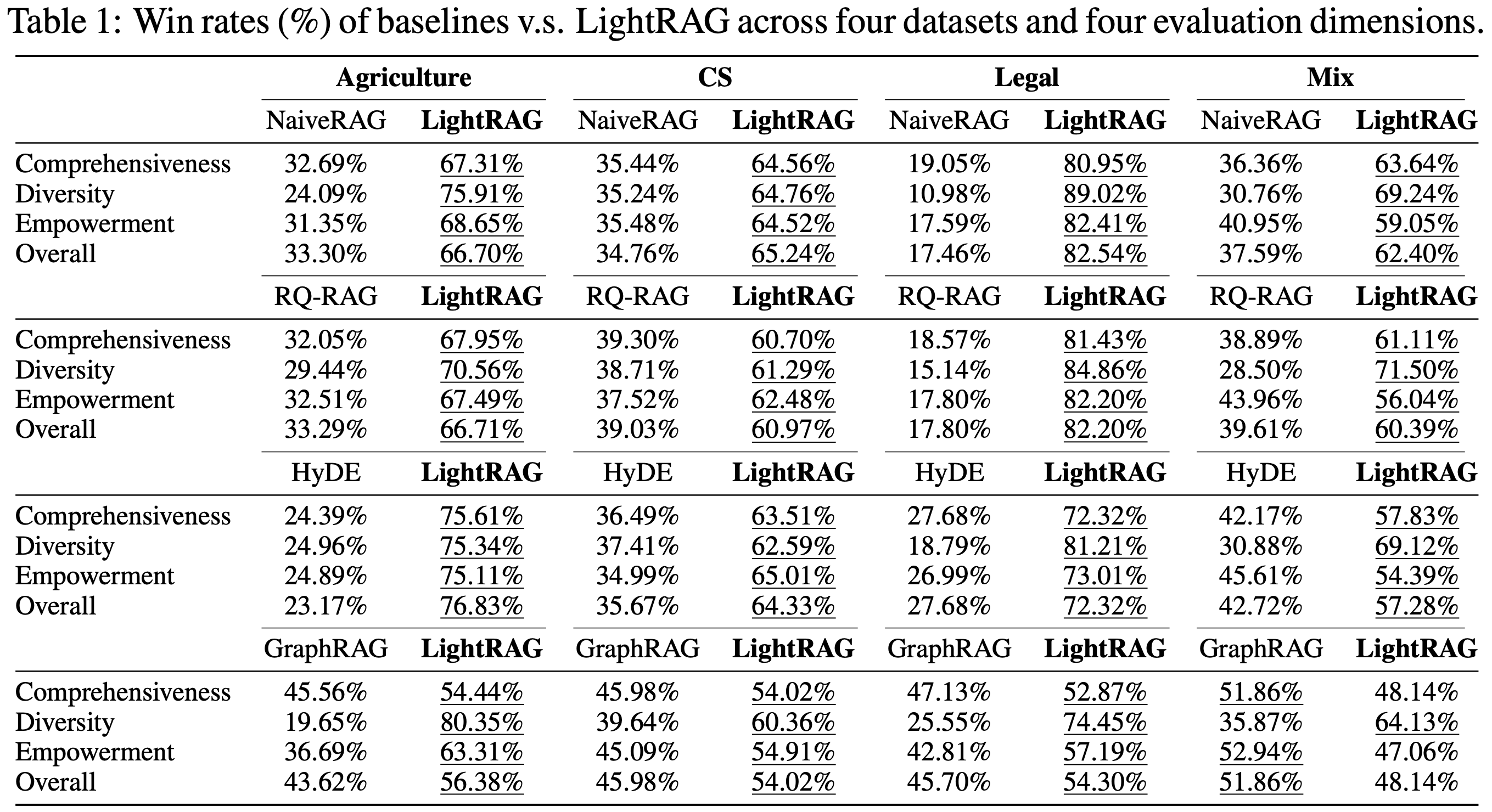
We compare LightRAG against each baseline across various evaluation dimensions and datasets. The results are presented in Table 1.
Ablation Study
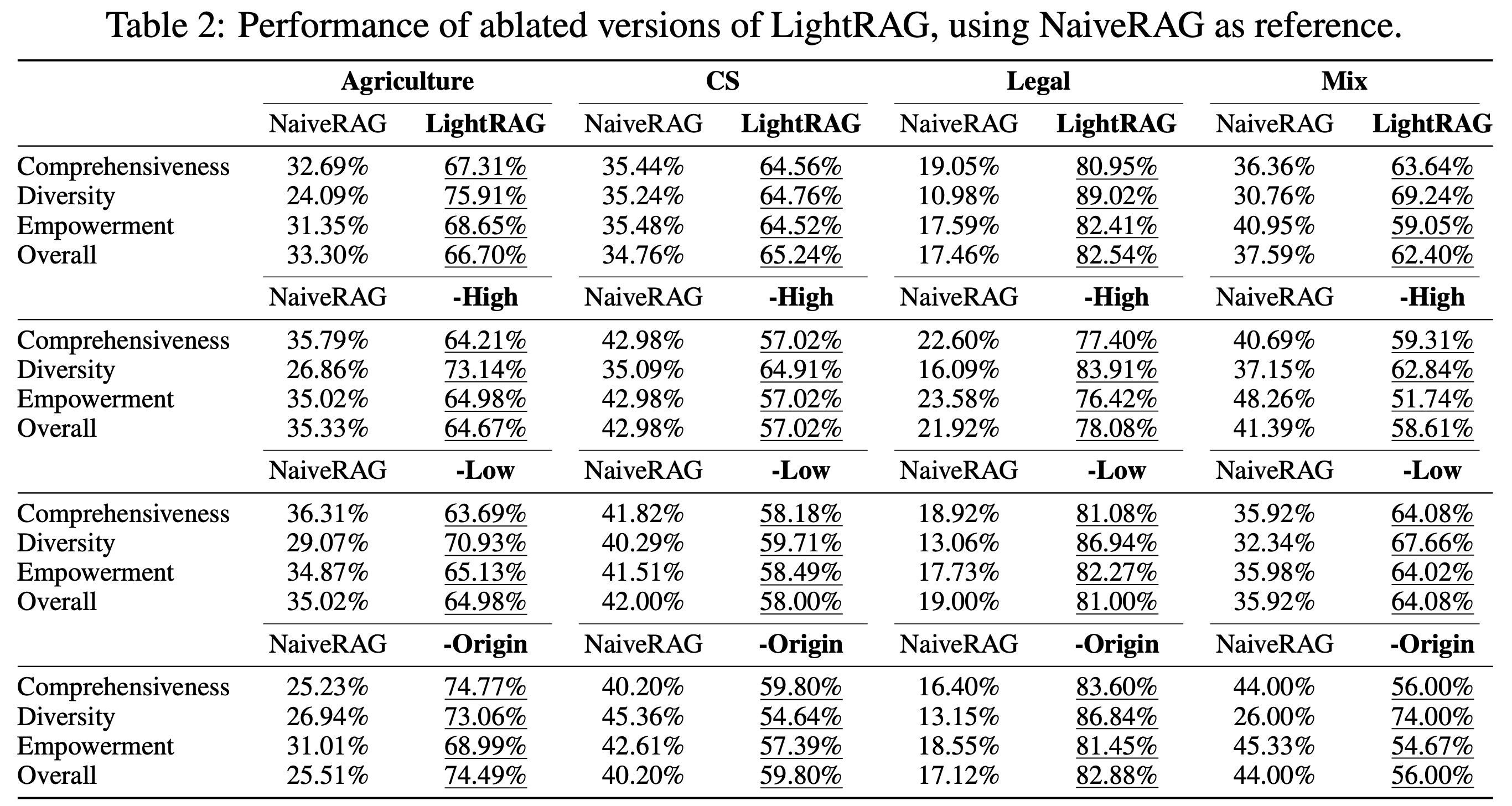
We begin by analyzing the effects of low-level and high-level retrieval paradigms. We compare two ablated models—each omitting one module—against LightRAG across four datasets. Here are our key observations for the different variants:
- Low-level-only Retrieval: The -High variant removes high-order retrieval, leading to a significant performance decline across nearly all datasets and metrics. This drop is mainly due to its emphasis on the specific information, which focuses excessively on entities and their immediate neighbors. While this approach enables deeper exploration of directly related entities, it struggles to gather information for complex queries that demand comprehensive insights.
- High-level-only Retrieval: The -Low variant prioritizes capturing a broader range of content by leveraging entity-wise relationships rather than focusing on specific entities. This approach offers a significant advantage in comprehensiveness, allowing it to gather more extensive and varied information. However, the trade-off is a reduced depth in examining specific entities, which can limit its ability to provide highly detailed insights. Consequently, this high-level-only retrieval method may struggle with tasks that require precise, detailed answers.
- Hybrid Mode: The hybrid mode, or the full version of LightRAG, combines the strengths of both low-level and high-level retrieval methods. It retrieves a broader set of relationships while simultaneously conducting an in-depth exploration of specific entities. This dual-level approach ensures both breadth in the retrieval process and depth in the analysis, providing a comprehensive view of the data. As a result, LightRAG achieves balanced performance across multiple dimensions.
Model Cost and Adaptability Analysis
We compare the cost of our LightRAG with that of the top-performing baseline, GraphRAG, from two key perspectives. First, we examine the number of tokens and API calls during the indexing and retrieval processes. Second, we analyze these metrics in relation to handling data changes in dynamic environments. The results of this evaluation on the legal dataset are presented in Table. In this context, \(T_{\text{extract}}\) represents the token overhead for entity and relationship extraction, \(C_{\text{max}}\) denotes the maximum number of tokens allowed per API call, and \(C_{\text{extract}}\) indicates the number of API calls required for extraction.
